商品详情页(下称商详)是展示商品详情信息的一个页面,整个购物流程比较重要的一个部分,承载着网站的绝大部分流量。为了提高转化率构成商详的元素非常丰富,有大量的图片、部分商品还有视频介绍、有相对静态的商详模板,有实时变化的价格、促销、库存。
 下面我们先来看下商详上一共有哪些元素组成?
下面我们先来看下商详上一共有哪些元素组成?
商详上的元素非常多,总结下来分为这么几个维度:商品维度(标题、主图、规格参数、商品文描)、分类维度、商家维度、店铺维度。另外还有一些实时性比较高的:价格、实时促销、配送地址、库存、广告等。
主要面临的挑战有:
高性能,商详页聚合服务比较多,要保证商详页在1-2秒内可以打开。
灵活性较好,可以快速响应页面变更需求。
具有较好的扩展性,当访问量增加的时候可以随时进行水平扩展。
要能够做到柔性降级,自带开关。某些底层服务出问题时可以通过开关进行相应降级处理。
针对商详可以有几种不同的实现方式,用户看到的是同一个商详页,但背后实现的方式却多种多样,下面给大家介绍几种常见的实现。
种实现方式:单机版
整个网站放在一台机器上,通过几条SQL分别拿到商详需要展示的各种信息,聚合成一个大的接口吐出给前端展示。
优点:逻辑简单。灵活性较好,可以快速响应页面变更需求。
缺点:性能比较差,没有扩展性。
第二种实现方式:缓存银弹
在版的基础上增加各种维度的缓存。可以将主图、商详的HTML模板放到CDN上,每个商品的聚合信息可以放到cache中,不需要每次请求都通过DB获取商品数据。
优点:可以一定程度上提高性能。
缺点:需要解决缓存与DB的数据一致性问题,单纯增加缓存面临数据实时性不高,底层数据已经修改,缓存中还不是新数据。若任何底层数据变更实时更新缓存则修改工作量较大。另外仍然没有解决扩展性问题。当请求量过大,或者商品数据过多将导致性能变差。
第三种实现方式:分布式服务化
按照领域进行切分,不同业务领域独立实现分别部署,将商详依赖的底层业务领域分别拆分出来。例如,商品、库存、促销、地址等分别进行服务化。每个子领域的服务自己保证各自的性能。
优点:具有很好的灵活性。当有业务需求变化的时候,每个子领域内部自行修改,对外部提供的接口协议不变,对外部无感知。并且具有良好的扩展性,当请求量或者数据量比较大的时候,每个子领域都可以分别进行横向扩展。
缺点:开发难度变大,由于按照领域进行服务划分,往往原来一行SQL可以搞定的事情。现在要涉及到多个领域一起配合来修改,需要协商接口协议,各个领域内部仍有不少开发量。
下面我们来说几个基本的概念,上面提到的服务到底是什么?
服务:自己自足的、无状态的业务功能,通过定义良好的标准接口,它接受一个或多个请求,返回一个或多个应答。
服务不应依赖于其他功能或过程;
用于提供服务的技术,编程语言,不构成定义的一部分;
服务体现了业务功能,聚焦于流程,服务的主要目标是体现业务功能的“自然”步骤。就服务起作用的业务而言,服务应该代表了一项自足的功能,对应着一项真实世界的业务活动,业务人员应该理解服务干了什么。
接口和契约(技术层面)
一项服务是一个处理(多个)消息的接口,返回信息,以及/或者改变实体(后端系统)的状态
前置条件、后置条件(安全意识,不信任原则)
粗粒度:有助于分离服务提供者的内部数据结构和外部接口
接口的版本、向后兼容
上面介绍了分布式服务化的方式来实现商详的技术架构,那么这样是不是就了?在实际情况下即使这种架构还是有很多不可控的因素会影响整个商详的性能。重要的一个就是对外部服务的依赖。如果外部服务出现抖动那么整个商详页也会随之出现不稳定。尤其商详是个比较大的聚合服务,底层依赖的服务比较多,任何一个出问题都会受到影响,那么商详出错的概率就会比较大。如何解决这个问题呢?
一种方案是要求所有底层服务各自保证自己的稳定性,这需要有比较完善的监控体系,能够快速找到出问题的点,然后进行修正。这种方案属于比较理想状态,对外部有强依赖。这需要有一个比较靠谱的团队,团队中每个人负责的领域稳定性、健壮性都比较高,那么这种方式是比较好的,领域的划分比较清晰,各自的职责也比较清晰。大家各自把自己的领域做好,那么整个网站的效率都比较高。
这对整个团队要求比较高,这种团队是存在的,但是当公司业务发展比较快,团队人数增长也比较快的时候,这时候团队的质量就比较难保证了,就会出现某一个领域或者某几个领域质量不是很高,就会导致整个服务调用链都不稳定,对整体网站影响较大。那么出现这种问题时如何解决呢?
互不信任原则
对外部不信任的原则是服务自我保护重要的方式,尽量降低外部服务出问题时对本服务的影响。对于一个写服务来说,一定要校验外部服务调用的所有参数是否合法,对每一个调用方分配场景ID记录调用来源,并且自己要做幂等去重处理。设计系统时先想到对于这个外部调用一旦失败该如何处理?是否有相应的降级策略?对于不同调用失败的场景一定要清晰记录错误信息方便后面调试跟踪解决问题。
数据闭环
数据闭环即数据的自我管理,或者说是数据都在自己系统里维护,不依赖于任何其他系统,去依赖化;这样得到的好处就是别人抖动跟我没关系。
数据异构:是数据闭环的步,将各个依赖系统的数据拿过来,按照自己的要求存储起来;
数据原子化:数据异构的数据是原子化数据,这样未来我们可以对这些数据再加工再处理而响应变化的需求;
数据聚合:将多个原子数据聚合为一个大JSON数据,这样前端展示只需要一次get,当然要考虑系统架构,比如使用Redis,Redis又是单线程系统,我们需要部署更多的Redis来支持更高的并发,另外存储的值要尽可能的小;
数据维度化:对于数据应该按照维度和作用进行维度化,这样可以分离存储,进行更有效的存储和使用。
下面是一种相对比较简单的维度的划分:
商品基本信息,标题、扩展属性、特殊属性、图片、颜色尺码、规格参数等;
商品介绍信息,商品维度商家模板、商品介绍等;
非商品维度其他信息,分类信息、商家信息、店铺信息、店铺头、品牌信息等;
商品维度其他信息(异步加载),价格、促销、配送至、广告词、推荐配件、理想组合等。
降级开关
当底层系统出现问题时候要能够做到通过开关的配置屏蔽底层系统的波动对商详的影响,例如当底层的库存系统出现问题时可以通过开关进行配置商详屏蔽调用库存接口,默认所有商品有库存,这样库存数量可能不是准确的,但至少可以保证用户正常浏览商详页不至于由于底层系统的波动导致整个商详页面打不开。在系统设计时候要尽可能的多预留降级开关,能降级的地方都要做好降级的准备,只有这样才能保证商详的高可用。
异步并发
假设一个读服务是需要如下数据:
数据A10ms
数据B15ms
数据C20ms
数据D5ms
数据E10ms
那么如果串行获取那么需要:60ms;
而如果数据C依赖数据A和数据B、数据D谁也不依赖、数据E依赖数据C;那么我们可以这样子来获取数据:
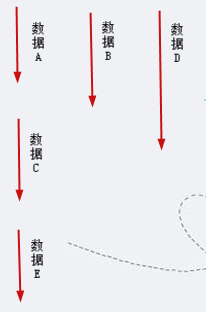
那么如果并发化获取那么需要:30ms;能提升一倍的性能。
假设数据E还依赖数据F(5ms),而数据F是在数据E服务中获取的,此时就可以考虑在此服务中在取数据A/B/D时预取数据F,那么整体性能就变为了:25ms。
网页设计
企业网站建设一条龙
找零度飞易网络公司-fslingdu所做php
网站建设方案、
网站设计、
网站制作由
北京上海深圳龙岗衢州兰州常州东营南通济宁桂林淮安烟台长春无锡天津昆山苏州合肥贵洛阳昆明天津唐山泉州惠州万州新乡商丘台州哈尔滨太原摄影海口随州学校商丘广东湖南广西江西海南广州企业中小企业武汉南山罗湖福田虎门肇庆汕尾汕头广州佛山成都杭州济南重庆福州西安厦门昆山沈阳青岛徐州郑州南京宁南宁长沙大连淄博石家庄南昌温州珠海番禺顺德南三水高明中山东莞合肥江门嘉兴西宁大良容桂伦教勒流陈村均安杏坛龙江乐从北滘祖庙石湾南庄等地区
企业网站建设(广告)公司提供专业做网站价格规划书及
营销型网站制作,
网站建设基础知识 下面我们先来看下商详上一共有哪些元素组成?
下面我们先来看下商详上一共有哪些元素组成? 那么如果并发化获取那么需要:30ms;能提升一倍的性能。
那么如果并发化获取那么需要:30ms;能提升一倍的性能。

















 零度飞易是一家专业网站设计,网站制作、seo优化,网站推广,网站建设的佛山网络运营公司。零度飞易在
零度飞易是一家专业网站设计,网站制作、seo优化,网站推广,网站建设的佛山网络运营公司。零度飞易在